

Нейросети сейчас используют с самыми разными целями — и для обработки фотографий, и для создания новостей, и для перевода. Регулярно появляются новости о том, что скоро искусственный интеллект во многих вещах сможет заменить человека. Насколько это правда и сможет ли машинный перевод составить конкуренцию переводчикам, Skyeng Magazine разобрался вместе с фестивалем Geek Picnic.
Вначале было слово
Знаете о «вавилонской рыбке» из «Автостопом по галактике»? Это существо, которое можно было поместить себе в ухо и получить возможность понимать все-все-все языки. Учитывая, как трудно порой дается английский (а это не самый сложный язык), подобная штука была бы очень кстати. И над ее созданием люди начали биться еще до появления компьютеров.
Советский ученый Петр Смирнов-Троянский в 1933 году создал «машину для подбора и печатания слов при переводе с одного языка на другой». Она состояла из карточек со словами на четырех языках (русский, английский, немецкий, испанский), печатной машинки с лентой и фотоаппарата. Оператор брал слова из текста, находил карточку, фотографировал ее, а на машинке печатал, какая это часть речи, число и падеж. Получившуюся ленту лингвисты превращали в текст.
Изобретение Троянского посчитали ненужным. Почти никто не знал о нем, пока патенты ученого не нашли в архивах. Собственно, даже этого не случилось бы, если бы СССР не нужно было искать ответ на вызов американцев в Холодной войне.

А потом появился машинный перевод
В 1954 году в Нью-Йорке прошел Джорджтаунский эксперимент. Компьютер IBM 701 перевел 60 предложений с русского языка на английский. В СМИ сразу появились статьи о том, что вскоре компьютеры заменят переводчиков — ну, вы же знаете журналистов. Но они понятия не имели, что предложения были тщательно подобраны, чтобы избежать любых ошибок.
Тем не менее, это привело к появлению дальнейших разработок. Капиталистические и социалистические страны соревновались в шпионаже, поэтому над системами перевода думали много. На самом деле, благодаря этому у нас сейчас есть интернет: первоначально его придумали в военных целях.


Легендарный PROMT
Программисты пытались заимствовать идеи у лингвистов. Так появился rule-based machine translation (машинный перевод на основе правил). По сути, они брали словарь и набор правил под каждый язык. Известные примеры подобных разработок — PROMT и Systran. Не нужно рассказывать, что итоговый перевод получался далеким от идеала. Иногда и вовсе выходил бред.
Взять хотя бы великий русский перевод GTA San Andreas. В оригинале герой говорит: «She's with me, cabron. So chill the fuck out. I treat her good». Если бы эту фразу переводил человек, то получилось бы примерно так: «Она со мной, козел. Так что остынь. Я хорошо с ней обращаюсь». Тем не менее, машина не понимала сленг и контекст. Испанское ругательство cabron он перепутала с carbon. В итоге получилось знаменитое «охладите траханье» и далее по списку.

Но и в таких переводах была польза. Во-первых, это смешно. Во-вторых, это показывало, что машины едва ли заменят людей в ближайшее время, так что никакое восстание нам пока не грозит. Да и шпионы могли быть спокойны: ведь если в деле участвовал машинный перевод, значит, можно не беспокоиться — информация в безопасности.
Были и другие идеи. Например, японцы в 80-х придумали example-based machine translation (машинный перевод на примерах). Они предлагали использовать множество уже имеющихся переводов различных конструкций и заменять в них необходимые слова, используя словарь. И не нужно тратить время на попытки обучить машину правилам. Такой вариант был лучше прошлых. Но все же до идеала неблизко.

Рождение гугл-транслейта
В 90-е появился statistical machine translation (статистический машинный перевод), который лег в основу всех ныне существующих онлайн-переводчиков. Ученые отказались обучать компьютер правилам и лингвистике. Они вбили в программу тысячи одинаковых текстов на двух языках, чтобы она сама разобралась с закономерностями. Чем больше текстов, тем лучше качество — переводы становятся логичнее.
Вот только это не решало многих проблем, например, с артиклями, вспомогательными глаголами и порядком слов в предложении. А еще языком-посредником во многих переводах выступал английский. В итоге получался эффект сломанного телефона. Вспомните развлечение: вставить текст на русском, перевести на английский и обратно. Если сделать так раз пять, итоговый текст вы можете не узнать.
Новости про ошибки в машинном переводе обычно вызывают много смеха. Что уж там, Google даже в рекламе невольно показал, что пока что настоящий переводчик куда лучше алгоритмов. Во время Супербоула зрителям показали ролик с переводами на разные языки, и фраза «Imported black farm-raised caviar» по-русски выглядела как «Импортные черный фермы подняли икра». Как видите, человек тут бы точно пригодился (хотя и люди допускают перлы в переводах).

Нейросеть предсказывает Апокалипсис
В 2016 году о нейросетях начали говорить все чаще. Google, в свою очередь, начал внедрять их в свой переводчик. Используя методы deep-learning (глубокое обучение), нейросеть можно обучать. Потом она сама уже непрерывно учится на собственных обработанных операциях и заимствует опыт других цифровых окружений.
Сейчас Google использует механизм «рекуррентных нейронных сетей». То есть переводчик учитывает контекст и еще множество других параметров, прежде чем выдать вариант перевода.
Нейронный перевод уже выглядит как заявка на успех в дальнейшем переводе. Кроме того, благодаря нейросетям можно переводить языки напрямую. Также в онлайн-версию Google Translate пользователи могут добавлять и свои переводы, и если ее одобрят другие — переводчик будет выбирать ее. Это не уберегает алгоритм от шутников. Но теперь он очень точно переводит повседневные фразы.
«Яндекс.Переводчик» тоже внедряет в работу нейросети. При этом в компании заявили, что используют гибридную систему. Предложение переводится сразу двумя методами — статистическим и нейросетевым. Потом алгоритм выбирает подходящий. Кроме того, «Яндекс» развлекается, добавляя в свой переводчик эльфийский и язык эмодзи. Ну а почему бы и нет?
Но без ошибок нейросеть пока тоже не обходится. И даже не просто ошибок — порой при переводе простых слов с языков, которые считаются редкими, гугл-транслейт начинает предсказывать конец света и вообще вести себя странно. Про подобные перлы есть даже телеграм-канал Neural Machine. Его автор вбивает бессмысленные сочетания, а в ответ получает странные фразы, претендующие то ли на философию, то ли на безумие.
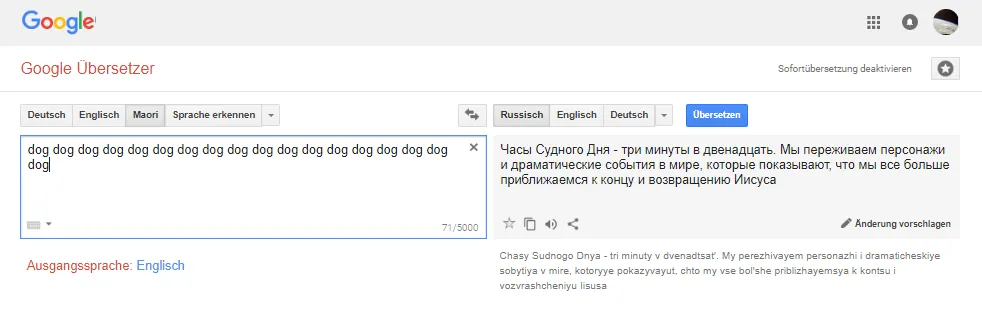
Разработчики официально подобные случаи не комментируют, но, возможно, дело в том, что система просто пытается совместить бессмыслицу с имеющимся у нее корпусом текстов. Да и тексты для перевода с редких языков (таковыми считаются, к примеру, монгольский и казахский) Google собирает при помощи добровольцев. Мало ли что они туда загружают. Тем не менее, нейросети по сравнению с остальными способами перевода — это целая революция.
Сейчас в Google работают над синхронным голосовым переводчиком. Подобные наработки уже есть у Skype. Но идеальный машинный перевод, тем более речи — это пока мечта. Так что знание английского все равно пригодится.
На научном фестивале Geek Picnic пройдут лекции про искусственный интеллект, нейросети и машинное обучение. Приходите и послушайте лекции про то, как машины учатся понимать человеческий язык, чем искусственный интеллект полезен в маркетинге и какое его ждет будущее. Читателям Skyeng Magazine мы дарим скидку 15% на билеты по промокоду AIGP. Воспользоваться предложением можно до 2 июля.















